Merging/joining data
At the heart of analysing linked data are merge or join operations. These are critical to extracting the necessary parts from each of the linked tables to get the final outputs required for analysis.
The following section provides a brief graphical summary of the three basic join types which you will typically need to use when working with or analysing linked data. Very simplified examples are used to highlight the differences between each type of join (Wickham & Grolemund, 2017).
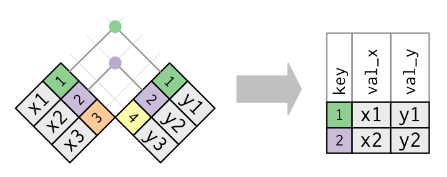
Inner join
- match on key variable[s]
- all non-matching keys and corresponding data discarded
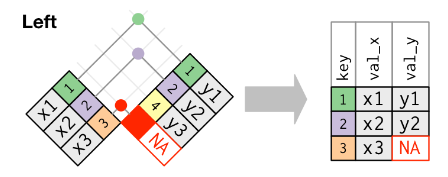
Left join (also known as a left outer join)
- match on key variable[s]
- keys and corresponding data from left-side retained
- all non-matching keys and corresponding data from right side discarded
(Reversing this order is a rarely used 'right-join' which is not necessary to understand)
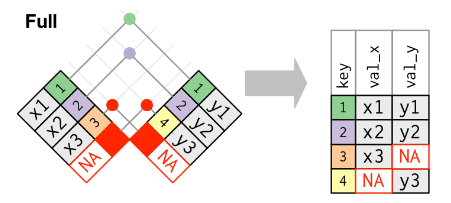
Full join (also known as a left full join)
- match on key variable[s]
- keys and corresponding data from both sides retained
Many-to-one and one-to-many joins
The joins described above can be complicated by multiple matches between values in the datasets being joined.
When this is true, you can end up with duplicated rows and possibly even more rows than are in either of the datasets you are joining together.
Consider that I want to do a mailout to a certain age-group in my cohort. I would have to join the 'Episode' table back on to the 'Cohort' table so I can access the 'birth_date' variable. In this instance I will use a 'left join' since I want to know about the 'Cohort' rows which do not have a date of birth recorded.
Since the 'birth_date's are repeated in the 'Episode' table for each new admission, each row with a matching 'id' in the 'Cohort' table will also be repeated. Giving:
Cohort + D.O.B data:
| id | research_id | birth_date |
| 1 | 1060 | 1982-03-13 |
| 1 | 1060 | 1982-03-14 |
| 2 | 1068 | 2000-01-01 |
| 2 | 1068 | 2000-01-01 |
| 3 | 2089 | 2010-06-12 |
| 4 | 3865 | 1968-09-28 |
| 5 | 2390 | N/A |
| 6 | 8907 | N/A |
Note how the values in the ‘research_id’ column are repeated for each time the corresponding ‘id’ was present in the ‘Patient’ table.
If I was to now use this table to calculate statistics about my whole ‘Cohort’, these duplicates would lead to overestimating the size of the cohort (8 cases instead of 6). Efforts must be made to remove the duplicate cases first so that my join gives me the desired result.
A simplistic solution may be to just select the distinct 'birth_date' value for each 'id' in the 'Patient' table. This will however typically fail in administrative datasets, as there can be conflicting information. Consider 'id' 1, which has both '1982-03-13' and '1982-03-14' recorded as the patient's 'birth_date'. A decision must be made as to which date is used, whether it is the earliest occurring date, the latest occurring date, the most commonly occurring date or some other logic. There is no definitive rule as to what is appropriate, with the decision dependent on your research aims and knowledge of the underlying data.